The first step is to ensure that your site can be found and crawled
by search engines. This is not as simple as it sounds, as there are many
popular web design and implementation constructs that the crawlers may not
understand.1. Indexable Content
To rank well in the search engines, your site’s content—that is,
the material available to visitors of your site—must be in HTML text
form. Images, Flash files, Java applets, and other nontext content is,
for the most part, virtually invisible to search engine spiders despite
advances in crawling technology.
Although the easiest way to ensure that the words and phrases you
display to your visitors are visible to search engines is to place the
content in the HTML text on the page, more advanced methods are
available for those who demand greater formatting or visual display
styles. For example, images in GIF, JPEG, or PNG format can be assigned
alt attributes in HTML, providing
search engines with a text description of the visual content. Likewise,
images can be shown to visitors as replacements for text by using CSS
styles, via a technique called CSS image
replacement.
2. Spiderable Link Structures
Website developers should invest the time to
build a link structure that spiders can crawl easily. Many sites make
the critical mistake of hiding or obfuscating their navigation in ways
that make spiderability difficult, thus impacting their ability to get
pages listed in the search engines’ indexes. Consider the illustration
in Figure 6-1 that
shows how this problem can occur.
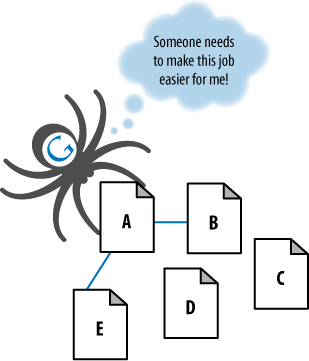
In Figure 1,
Google’s spider has reached Page A and sees links to pages B and E.
However, even though pages C and D might be important pages on the site,
the spider has no way to reach them (or even to know they exist) because
no direct, crawlable links point to those pages. As far as Google is
concerned, they might as well not exist—great content, good keyword
targeting, and smart marketing won’t make any difference at all if the
spiders can’t reach those pages in the first place.
Links in submission-required forms
Search spiders will not attempt to “submit” forms, and thus,
any content or links that are accessible only via a form are
invisible to the engines. This even applies to simple forms such
as user logins, search boxes, or some types of pull-down
lists.
Links in nonparsable JavaScript
If you use JavaScript for links, you may find that search
engines either do not crawl or give very little weight to the
links embedded within them.
Links in Flash, Java, or other plug-ins
Links embedded inside Java and plug-ins are invisible to the
engines. In theory, the search engines are making progress in
detecting links within Flash, but don’t rely too heavily on
this.
Links in PowerPoint and PDF files
PowerPoint and PDF files are no different from Flash, Java,
and plug-ins. Search engines sometimes report links seen in
PowerPoint files or PDFs, but how much they count for is not
easily known.
Links pointing to pages blocked by the meta Robots tag, rel="NoFollow", or robots.txt
The robots.txt file
provides a very simple means for preventing web spiders from
crawling pages on your site. Use of the NoFollow attribute on a link, or
placement of the meta Robots
tag on the page containing the link, is an instruction to the
search engine to not pass link juice via the link.
Links on pages with many hundreds or thousands of links
Google has a suggested guideline of 100 links per page
before it may stop spidering additional links from that page. This
“limit” is somewhat flexible, and particularly important pages may
have upward of 150 or even 200 links followed. In general,
however, it is wise to limit the number of links on any given page
to 100 or risk losing the ability to have additional pages
crawled.
Links in frames or iframes
Technically, links in both frames and iframes can be
crawled, but both present structural issues for the engines in
terms of organization and following. Unless you’re an advanced
user with a good technical understanding of how search engines
index and follow links in frames, it is best to stay away from
them as a place to offer links for crawling purposes. .
6.1.3. XML Sitemaps
Google, Yahoo!, and Microsoft all support a protocol known as XML
Sitemaps. Google first announced it in 2005, and then Yahoo! and
Microsoft agreed to support the protocol in 2006. Using the Sitemaps
protocol you can supply the search engines with a list of all the URLs
you would like them to crawl and index.
Adding a URL to a Sitemap file does not guarantee that a URL will
be crawled or indexed. However, it can result in pages that are not
otherwise discovered or indexed by the search engine getting crawled and
indexed. In addition, Sitemaps appear to help pages that have been
relegated to Google’s supplemental index make their way into the main
index.
This program is a complement to, not a replacement for, the search
engines’ normal, link-based crawl. The benefits of Sitemaps include the
following:
For the pages the search engines already know about through
their regular spidering, they use the metadata you supply, such as
the last date the content was modified (lastmod
date) and the frequency at which the page is changed
(changefreq), to improve how they crawl your
site.
For the pages they don’t know about, they use the additional
URLs you supply to increase their crawl coverage.
For URLs that may have duplicates, the engines can use the XML
Sitemaps data to help choose a canonical version.
Verification/registration of XML Sitemaps may indicate
positive trust/authority signals.
The crawling/inclusion benefits of Sitemaps may have
second-order positive effects, such as improved rankings or greater
internal link popularity.
The Google engineer who in online forums goes by GoogleGuy (a.k.a.
Matt Cutts, the head of Google’s webspam team) has explained Google
Sitemaps in the following way:
Imagine if you have pages A, B, and C on your site. We find
pages A and B through our normal web crawl of your links. Then you
build a Sitemap and list the pages B and C. Now there’s a chance (but
not a promise) that we’ll crawl page C. We won’t drop page A just
because you didn’t list it in your Sitemap. And just because you
listed a page that we didn’t know about doesn’t guarantee that we’ll
crawl it. But if for some reason we didn’t see any links to C, or
maybe we knew about page C but the URL was rejected for having too
many parameters or some other reason, now there’s a chance that we’ll
crawl that page C.
Sitemaps use a simple XML format that you can learn about at
http://www.sitemaps.org. XML Sitemaps are a useful
and in some cases essential tool for your website. In particular, if you
have reason to believe that the site is not fully indexed, an XML
Sitemap can help you increase the number of indexed pages. As sites grow
in size, the value of XML Sitemap files tends to increase dramatically,
as additional traffic flows to the newly included URLs.
3.1. Layout of an XML Sitemap
The first step in the process of creating an XML Sitemap is to
create an .xml Sitemap file in a
suitable format. Since creating an XML Sitemap requires a certain
level of technical know-how, it would be wise to involve your
development team in the XML Sitemap generator process from the
beginning. Figure 2 shows
an example of some code from a Sitemap.

To create your XML Sitemap, you can use the following:
An XML Sitemap generator
This is a simple script that you can configure to
automatically create Sitemaps, and sometimes submit them as
well. Sitemap generators can create these Sitemaps from a URL
list, access logs, or a directory path hosting static files
corresponding to URLs. Here are some examples of XML Sitemap
generators:
Simple text
You can provide Google with a simple text file that
contains one URL per line. However, Google recommends that once
you have a text Sitemap file for your site, you use the Sitemap
Generator to create a Sitemap from this text file using the
Sitemaps protocol.
Syndication feed
Google accepts Really Simple Syndication (RSS) 2.0 and
Atom 1.0 feeds. Note that the feed may provide information on
recent URLs only.
3.2. What to include in a Sitemap file
When you create a Sitemap file you need to take care to include
only the canonical version of each URL. In other words, in situations
where your site has multiple URLs that refer to one piece of content,
search engines may assume that the URL specified in a Sitemap file is
the preferred form of the URL for the content. You can use the Sitemap
file as one way to suggest to the search engines which is the
preferred version of a given page.
In addition, be careful about what not to include. For example,
do not include multiple URLs that point to identical content; leave
out pages that are simply pagination pages, or alternate sort orders
for the same content, and/or any low-value pages on your site. Plus,
make sure that none of the URLs listed in the Sitemap file include any
tracking parameters.
3.3. Where to upload your Sitemap file
When your Sitemap file is complete, upload the file to your site
in the highest-level directory you want search engines to crawl
(generally, the root directory). If you list URLs in your Sitemap that
are at a higher level than your Sitemap location, the search engines
will be unable to include those URLs as part of the Sitemap
submission.
3.4. Managing and updating XML Sitemaps
Once your XML Sitemap has been accepted and your site has been
crawled, monitor the results and update your Sitemap if there are
issues. With Google, you can return to http://www.google.com/webmasters/sitemaps/siteoverview
to view the statistics and diagnostics related to your Google
Sitemaps. Just click the site you want to monitor. You’ll also find
some FAQs from Google on common issues such as slow crawling and low
indexation.
Update your XML Sitemap with the big three search engines when
you add URLs to your site. You’ll also want to keep your Sitemap file
up-to-date when you add a large volume of pages or a group of pages
that are strategic.
There is no need to update the XML Sitemap when simply updating
content on existing URLs. It is not strictly necessary to update when
pages are deleted as the search engines will simply not be able to
crawl them, but you want to update them before you have too many
broken pages in your feed. With the next update after adding new
pages, however, it is a best practice to also remove those deleted
pages; make the current XML Sitemap as accurate as possible.
3.4.1. Updating your Sitemap with Bing
Simply update the .xml
file in the same location as before.
3.4.2. Updating your Google Sitemap
You can resubmit your Google Sitemap using your Google
Sitemaps account, or you can resubmit it using an HTTP
request:
From Google Sitemaps
Sign into Google Webmaster Tools with your Google
account. From the Sitemaps page, select the checkbox beside
your Sitemap filename and click the Resubmit Selected button.
The submitted date will update to reflect this latest
submission.
From an HTTP request
If you do this, you don’t need to use the Resubmit link
in your Google Sitemaps account. The Submitted column will
continue to show the last time you manually clicked the link,
but the Last Downloaded column will be updated to show the
last time Google fetched your Sitemap. For detailed
instructions on how to resubmit your Google Sitemap using an
HTTP request, see http://www.google.com/support/webmasters/bin/answer.py?answer=34609.
Google and the other major search engines discover and index
websites by crawling links. Google XML Sitemaps are a way to feed
the URLs that you want crawled on your site to Google for more
complete crawling and indexation, which results in improved long
tail searchability. By creating and updating this .xml file, you are helping to ensure that
Google recognizes your entire site, and this recognition will help
people find your site. It also helps the search engines understand
which version of your URLs (if you have more than one URL pointing
to the same content) is the canonical version.